Introduction
As we start September, the UK situation regarding Covid-19 cases and deaths has changed somewhat.
Since the UK Government re-assessed the way deaths data is collected and reported, the reported daily deaths resulting from Covid-19 infections have (thankfully) reduced to a very low level, as we see from the UK Government Covid-19 reporting website.
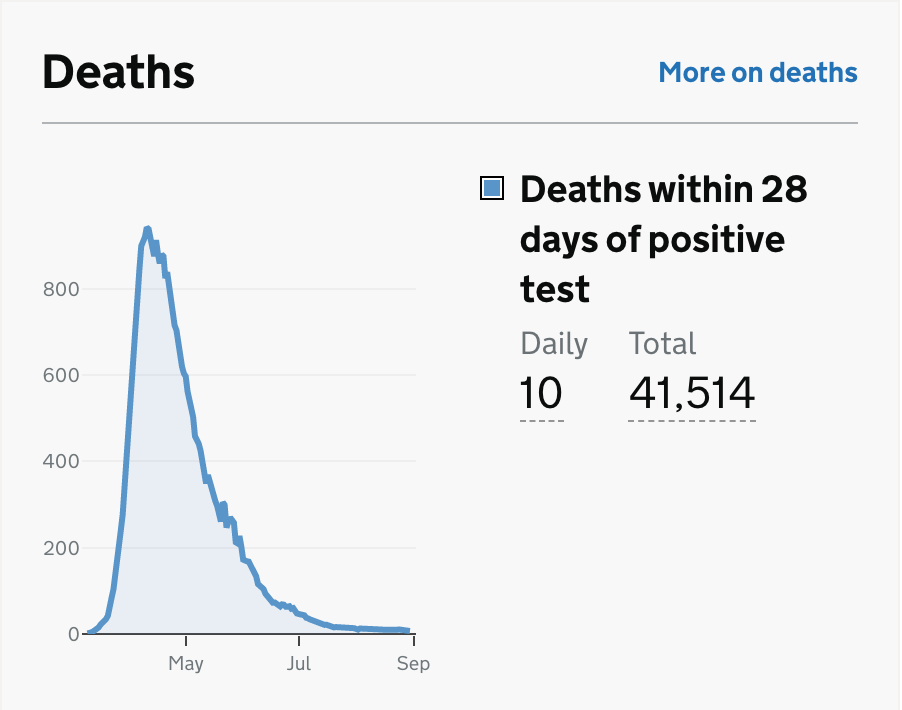

Cases, however, as we see from the Government chart on the right, have started to rise again, although for a number of reasons the impact on deaths has been less than before. Note that the Cases chart plots people testing positive (daily and total to date) against time.
I have integrated this real world UK reported data with my model data to assess what is happening.
Reporting changes for UK deaths
As I reported in my August 17th post, reported daily deaths in England had previously set no time limit between any individual’s positive test for Covid-19, and when that person died.
The three other home countries in the UK had already been applying a 28-day limit for this interval. It was felt that, for England, this lack of a limit on the time interval resulted in over-reporting of deaths from Covid-19. Even someone who had died in a road accident, say, would have been reported as a Covid-19 death if they had ever tested positive, and had then recovered from Covid-19, no matter how long before their death the positive test had occurred.
This adjustment to the reporting was applied retroactively in England for all reported daily deaths, which resulted in a cumulative reduction of c. 5,000 in the UK reported deaths to up to August 12th.
Case numbers and antibody testing
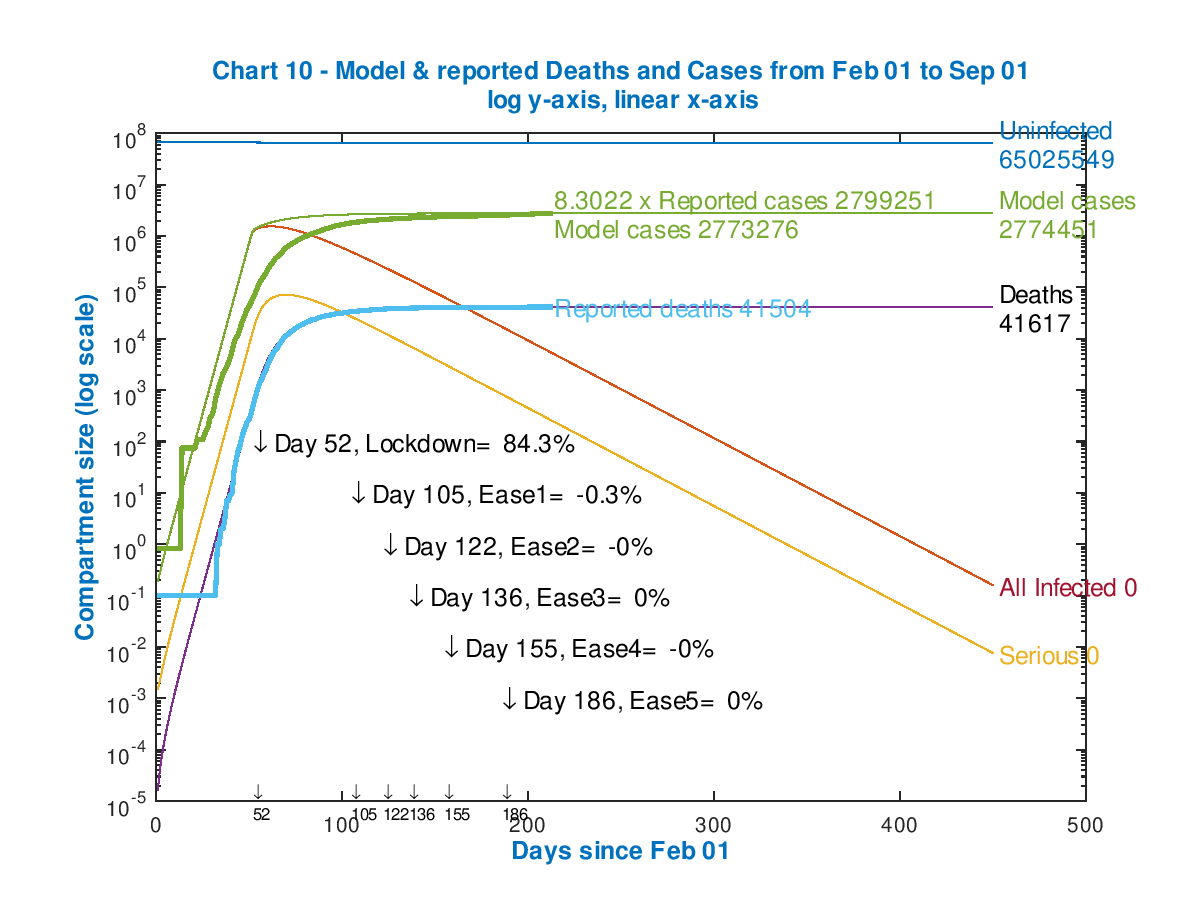
You can see from the following chart 10 that the plateau for modelled cases is of the order of 3 million. This startling view is supported by a recent Imperial College antibody study reported by U.K. Government here.
I have applied a factor of 8.3 to the reported cases in Chart 10 to bring them into line with the modelled cases, owing to significant under-reporting of the number of UK cases (based on positive Covid-19 tests).

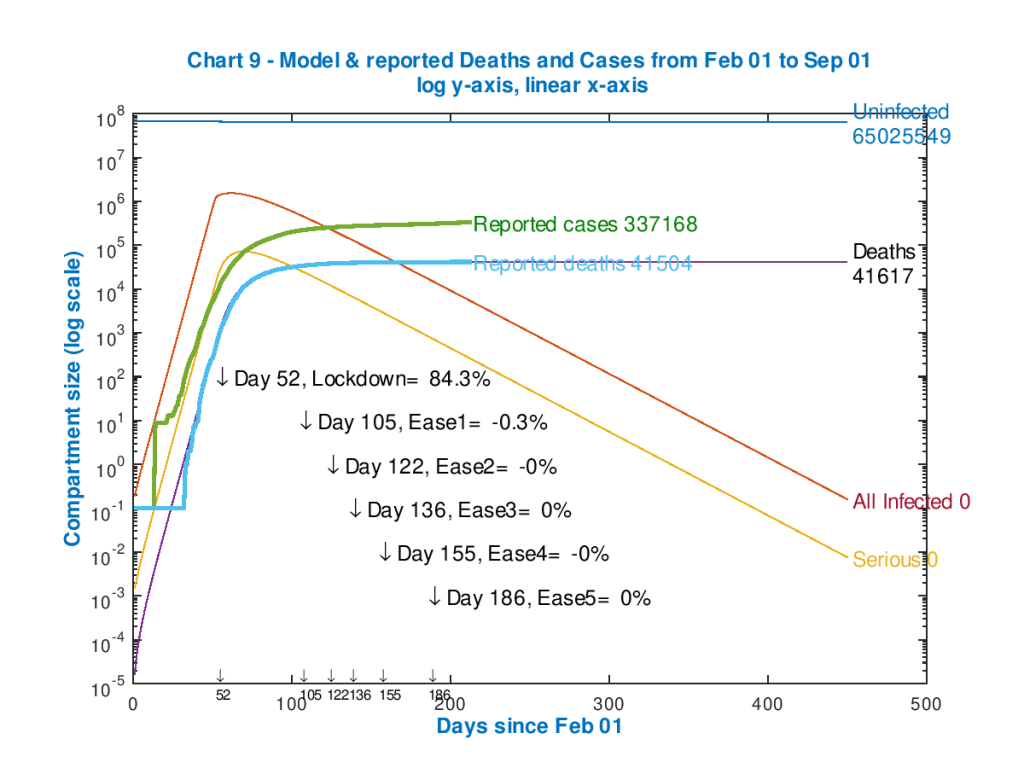
The reported cases (defined by UK Government as people who have had a positive Covid-19 test) are just 337,168 as at September 1st, as we see from the following chart 9.
Testing, antibodies, and counting cases
The four pillars of Covid-19 testing include a single pillar of antibody testing, although it isn’t clear exactly which class of antibody is being tested. Not all antibody tests are the same.
It is also the case that despite more than 16 million Covid-19 tests having been processed in the UK to date (September 1st), the great majority of people have never been tested.
The under-reporting of cases (defining cases as those who have ever had Covid-19) was, in effect, confirmed by the major antibody testing programme, led by Imperial College London, involving over 100,000 people, finding that just under 6% of England’s population – an estimated 3.4 million people – had antibodies to Covid-19, and were likely previously to have had the virus, prior to the end of June.
Even my modelled cases are likely to be a little under-estimated, and some update to my model’s calculation of cases will be made shortly.
Quite apart from the definition and counting of cases, according to a recent report by The Times, referencing this article from the BMJ, results obtained from some antibody testing might well be under-estimated too.
Stephen Burgess, from the Medical Research Council Biostatistics Unit at Cambridge University, and one of the authors, said. “It’s possible that somebody could have antibodies present in their saliva but not in their blood and it’s possible that somebody could have one class of antibody but not another class of antibodies.”
In particular, most antibody tests do not look for a type of response called IgA antibodies, which are made in mucus — in the mouth, eyes and nose. “In certain respiratory diseases, it’s well-documented that it’s possible to beat the infection with an IgA response,” he said.
When scientists have tested for IgA as well as the standard IgG antibodies, they have on occasions found hugely different results. In Luxembourg, IgA were found in 11 per cent of people compared with 2 per cent who tested positive using more conventional tests.
Dr Burgess said that calibrating tests using people who had been more severely ill may mean that a lot of asymptomatic infections are being missed.
The Times concludes that it’s possible that herd immunity is closer than we think, with regional variations.
Reported Cases and Deaths
The following slide presentation shows only reported data for the UK. With Tom Sutton’s help, I have managed to link his previously developed Worldometers scraping code, which interrogates the daily updated Worldometers site for the UK, to retrieve Cases and Deaths data, to populate my MatLab/Octave model for Coronavirus, originally developed by Prof Alex de Visscher at Concordia University, Montreal.
This allows me to plot both modelled forecast data and reported data on the same charts, plotted from from the Octave forecasting model.

Reported UK Deaths vs.Cases since Feb 15th 2020, log chart 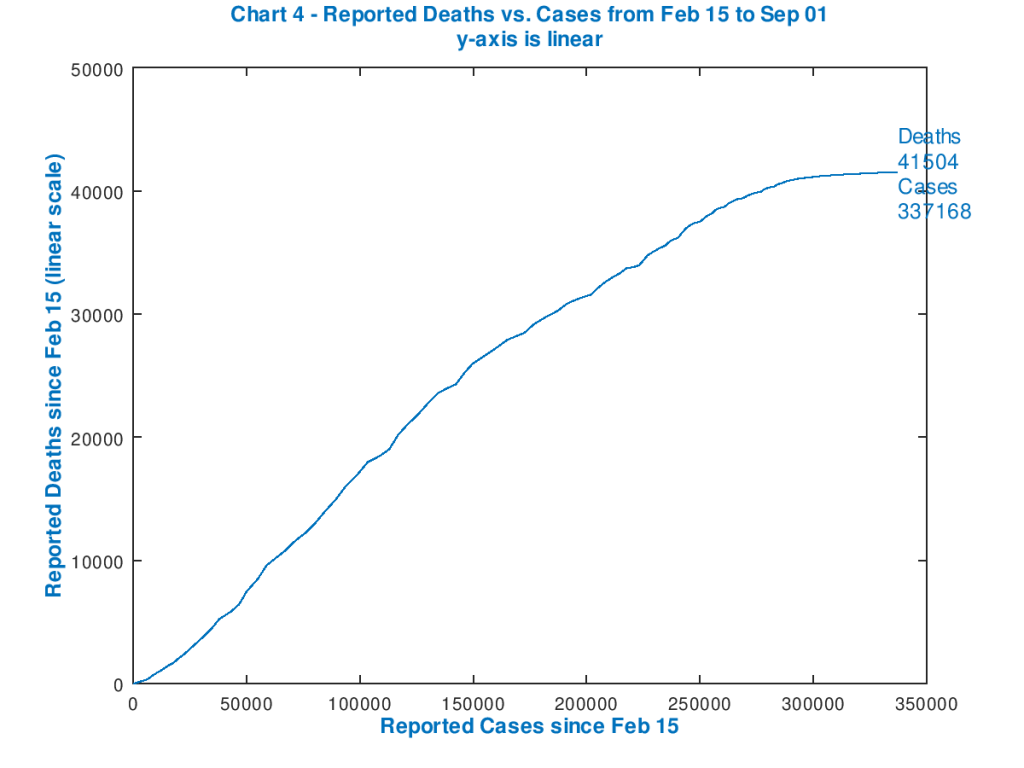
Reported UK Deaths vs.Cases since Feb 15th 2020, linear chart 
Reported UK Deaths since Feb 15th 2020, linear chart 
Reported UK Cases and Deaths since Feb 15th 2020, dual axis, log deaths, linear cases 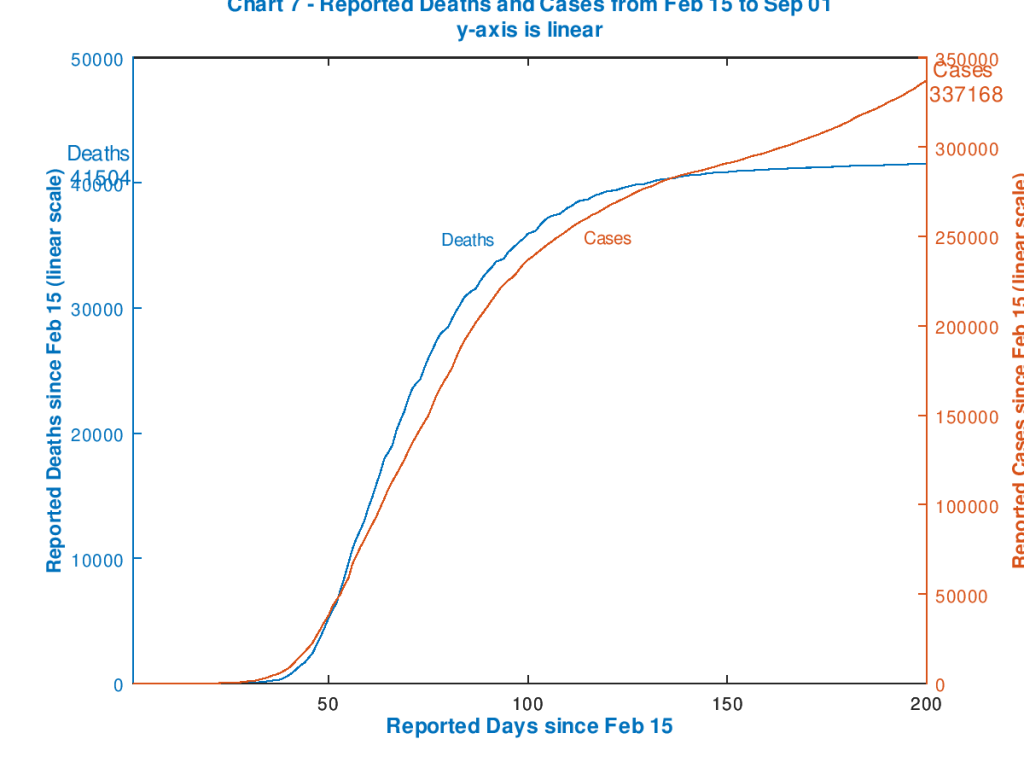
Reported UK Cases and Deaths since Feb 15th 2020, linear dual-axis chart 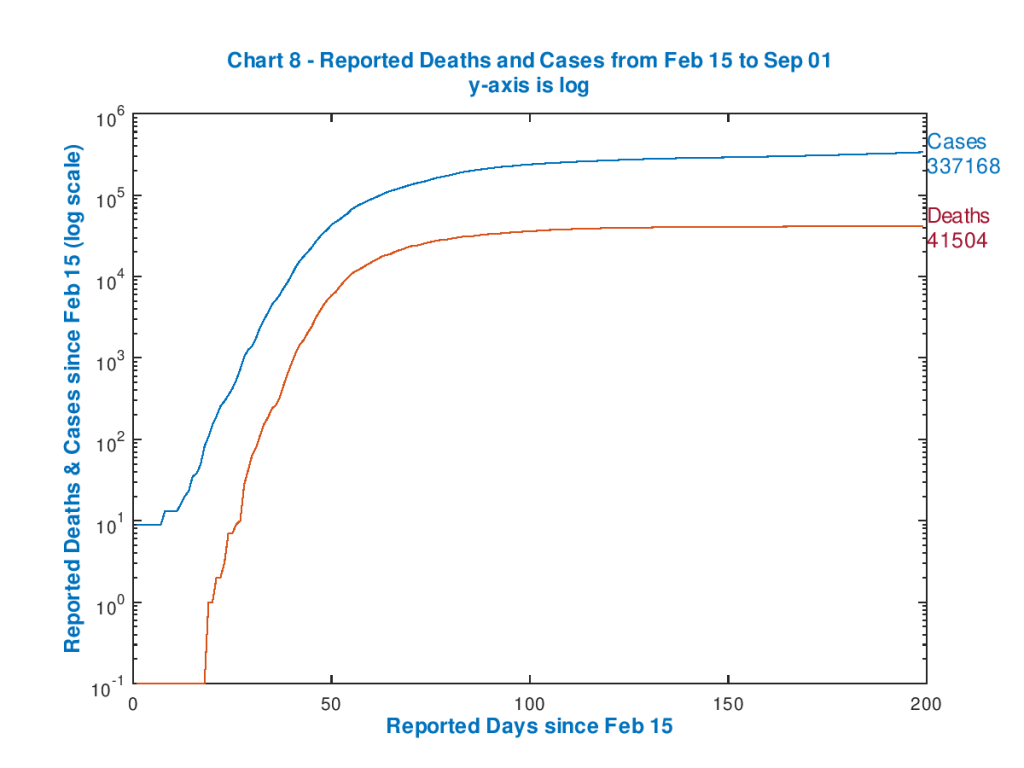
Reported UK Cases and Deaths since Feb 15th 2020, log chart
Chart 3 shows Reported Deaths plotted against cases, on a log chart, and shows the log curve for Deaths flattening as cumulative Cases (on the linear x-axis) increase over time, indicating that the ratio of deaths/cases is reducing. This can also be seen very clearly on the linear scaled Chart 4.
Chart 5 shows cumulative deaths over time on linear axes, exhibiting the typical S-curve for infectious diseases; as of September 1st, daily deaths are in single figures.
Chart 6 shows Deaths on a log y-axis (left) and Cases on a linear y-axis (right).
Chart 7 plots both deaths and cases on linear y-axes (left and right respectively) for more direct comparison, and again we see that recently, since about Day 110 (June 1st), cases have increased proportionately much faster than deaths. This date is fairly close to the time that the UK started to ease its lockdown restrictions.
Finally, Chart 8, plotting both deaths and cases on the same log y-axis, shows the relative progression over nearly 200 days since the onset of the pandemic.
These different views clearly show the recent changes in the way the epidemic is playing out in the UK population. Bear in mind that reported cases need something like a factor of 10 applied to bring them to a realistic figure.
Evidence for the under-estimation of Cases
The Imperial College antibody study referenced above is also in line with the estimate made by Prof. Alex de Visscher, author of my original model code, that the number of cases is typically under-reported by a factor of 12.5 – i.e. that only c. 8% of cases are detected and reported, an estimate assessed in the early days for the Italian outbreak, at a time when “test and trace” wasn’t in place anywhere.
A further sanity check on my forecasted case numbers, relative to the forecasted number of deaths, would be the observed mortality from Covid-19 where this can be assessed.
A study by a London School of Hygiene & Tropical Medicine team carried out an analysis of the Covid-19 outbreak in the closed community of the Diamond Princess cruise ship in March 2020.
Adjusting for delay from confirmation-to-death, this paper estimated case and infection fatality ratios (CFR, IFR) for COVID-19 on the Diamond Princess ship as 2.3% (0.75%-5.3%) and 1.2% (0.38-2.7%) respectively. See the World Health Organisation (WHO) description of CFR & IFR here.
In broad terms, my model forecast of c. 42,000 deaths and up to 3 million cases would be a ratio of about 1.4%, and so the IFR relationship between the deaths and cases numbers in my charts seems reasonable.
(NB since we know that the risk of death from Covid-19 is higher in older people, and the age profile of cruise ship passengers is probably higher than average, the Diamond Princess percentages are at the high end of the spectrum.)
Reasons for the reducing deaths/cases ratio
Reported deaths per case are reducing significantly, because:
a) we are more aware of taking care of older people in Care Homes (and certainly not knowingly sending Covid-19 positive old folks to them), sadly lacking in the early days, in many countries;
b) relatively more young people are being infected as compared with older people because they are the ones working, and going out more, and they have lower mortality than older people;
c) we have some better experience and palliative treatments to help some people recover (eg Dexamethasone as described at https://www.sps.nhs.uk/articles/summary-of-covid-19-medicines-guidance-critical-care/); and
d) daily cases are increasing, rather than reducing, as deaths are.
This is covered in a very good article by Rowland Manthorpe, technology correspondent, and Isla Glaister, data editor of Sky News, whose reports I have read before. The article makes very clear the changes in the age-dependency of cases from early March to the end of July.

Another view of this is from The Times on September 5th, data sourced from Public Health England (PHE);
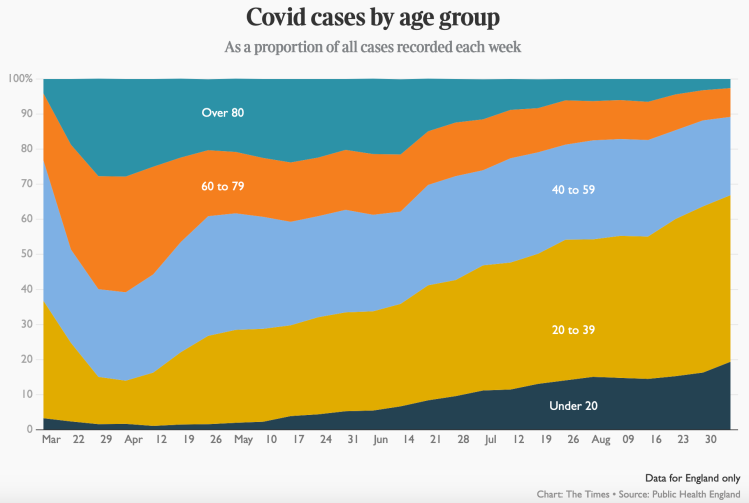
and, more specifically, here is how the proportion of cases has shifted between under 40s and over 50s from March until September.

Issues for modelling presented by local spikes
Modelling the epidemic for the UK is now really difficult, as most cases having an impact on the UK national statistics are nearly all caused by local outbreaks – what I call multiple super-spreader events. Although that isn’t quite the right description, these are being caused by behaviour such as lack of social distancing, and maybe erratic mask-wearing on flights returning to the UK with pre- and even post-diagnostic cases on board.
The super-spreader events in the early days in Italy (and in the UK) were caused by people unknowingly and asymptomatically infected, returning to their home countries from overseas.
These more recent events are caused, it seems to me, by people who ought nowadays to have more awareness of the risks, and know better, compared to those in the early days.
What would be needed to model such events is good local data for each one, and some kind of model for how, when and how often, statistically, these events might occur (aircraft, pubs, clubs, demonstrations, illegal raves and all the rest). Possibly even religious gatherings and other such cultural (including sporting) gatherings have a role.
So modelling this bottom-up is difficult – but feasible, hopefully. In any case, what is needed at the moment is a time-dependent way of handling the infection risks, in the context of these events, the way that lockdown easing points have been introduced to the model.
Worldometers/IHME forecasts and charts
I might say that modelling only by curve fitting, top-down, is pretty incomplete in my view. Phenomenological methods forecast the future based on the past with no ability to model or reflect changes in intervention methods, public behaviour and responses; and I see no capability in the methodology to take super-spreader events into account.
This might be difficult for bottom-up mechanistic modelling, but it’s impossible for broad, country-based curve-fitting, as no link can be made from input changes in government measures, population responses and individual behaviour, to their influence on outcomes.
I covered the comparative phenomenological and mechanistic methods in my previous posts on July 14th and July 18th.
In the charts that follow, we see that forecasts are made for three scenarios: current projections; mandates easing; and universal masks.
To do this, as IHME (Institute for Health Metrics and Evaluation at the University of Washington, USA) say at the IHME FAQ (Frequently Asked Questions) page, Worldometers/IHME forecasts rely on both statistical and disease transmission models: “Our current model is not a disease transmission model. It is a hybrid model that combines both a statistical modeling approach and a disease transmission approach, leveraging the strengths of both types of models, and scaling the results of the disease transmission model to the results of the statistical model.“
This enables them to calibrate outcomes based on three outbreak management scenarios.
Illustrating the point, I show the IHME forecast for the UK, followed by that for the USA . First the UK:

It seems that IHME forecasts for the UK, linked to the Worldometers UK site, are based on a broader view of UK deaths, relating to those where Covid-19 is mentioned on the death certificate, as defined by the UK Office for National Statistics (ONS), but not necessarily cited as the cause of death.
This is even though the Worldometers current reporting charts themselves are consistent with UK Government reported data, which presents deaths in all settings (including hospitals, care homes and the community) but only when Covid-19 is cited as the cause of death.
The ONS and IHME numbers are higher than the UK Government (and Worldometers) statistic. The daily numbers I have been using, presented by the UK Government, continue to be based on the narrower definition – Covid-19 as the cause of death on the death certificate.
Nevertheless, my main point here isn’t about the absolute numbers, but about the forecasting scenarios. We can see that the IHME methodology allows for several forecasting scenarios – current projections based on the interventions currently in place; mandates easing; and universal mask-wearing.
The US IHME forecast is presented similarly:

In the case of the USA, the numbers are far larger for a much bigger population, and at worst the numbers are staggering. The Covid-19 deaths, currently 187,770 on this chart, had already exceeded Michael Levitt’s well-publicised curve-fitting Twitter forecast made in mid-July, indicating that by August 25th the USA excess deaths will have reduced to a very low level, and that the USA experience of the pandemic would essentially be over, with 170,000 deaths. It seems he agrees that forecast, or at least the way he expressed it, was a mistake.


See Michael’s new UnHerd interview on this topic with Freddie Sayers.
As for excess deaths, no measure is without its issues, and the problem there is that Covid-19 deaths will probably have replaced deaths from some other causes (people go out less, so there will be less road accident deaths, for example).
This means that excess deaths reducing to zero isn’t by any means a sufficient test that the SARS-Cov-2 pandemic is all over bar the shouting.
IHME can predict several scenarios, as for the UK, and at best they are predicting 288,381 deaths by the end of the year for the USA. At worst their number is over 600,000. I’m sure things wouldn’t be allowed to get to that.
But these kinds of scenarios for different potential interventions, in combinations, or when eased, just aren’t going to work with curve-fitting alone, where, given just 3 (or at best, 4) parameters to do a least-squares fit of a Cycloid, Gompertz or more general Richards / General Logistics curve to the reported data, any changes to Government interventions and/or public response (even nationally, let alone for local spikes) can’t be reflected. It’s a top-down view of reported data (however well-cleansed) not a bottom-up causation model with the ability to make variations to strategies for intervention.
Mechanistic modelling is hard to do, takes longer and is more expensive in computer time (especially when trying to cover many countries individually); that is where a broader helicopter top-down view from curve-fitting can help to get started. But curve-fitting is not an actionable model for deciding between intervention methods.
I covered these methods in my blog posts on July 14th and July 18th as I was sanity checking my own outlook on modelling methods as between mechanistic modelling (the broad type of the model I use) and phenomenological / statistical methods.
The Imperial College resources
As I have already reported in my blog post on July 18th, Imperial College (and others such as The London School of Hygiene and Tropical Medicine) use a variety of model types and data sources (as do IHME) spanning both mechanistic and statistical methods (which include phenomenological techniques) for forecasts at different levels of detail and over different periods. These are described at the Imperial College’s Medical Research Council MRC Global Infectious Disease Analysis website, where this chart is presented, describing their different methods:

and they go on to describe the key characteristics of the approaches:
“Mechanistic model: Explicitly accounts for the underlying mechanisms of diseases transmission and attempt to identify the drivers of transmissibility. Rely on more assumptions about the disease dynamics.
“Statistical model: Do not explicitly model the mechanism of transmission. Infer trends in either transmissibility or deaths from patterns in the data. Rely on fewer assumptions about the disease dynamics.
“Mechanistic models can provide nuanced insights into severity and transmission but require specification of parameters – all of which have underlying uncertainty. Statistical models typically have fewer parameters. Uncertainty is therefore easier to propagate in these models. However, they cannot then inform questions about underlying mechanisms of spread and severity.“
The forecasts they have made, as you can see, just as the IHME forecasts do, rely on several methodologies.
The table I have shown before from the pivotal Imperial College modelling team March 16th paper:

shows the capability to model a range of Non Pharmaceutical Interventions (NPIs) alone or in different combinations to arrive at forecasts based on such strategies. I covered the NPI variations in some detail in my August 14th blog post, and the mechanistic, statistical and phenomenological approaches in my July 14th blog post and July 18th post.
Discussion
My UK model is tracking quite well after a small change in intervention effectiveness since March 23rd to reflect the retroactive August 12th Government changes in counting deaths, and a slight easing on day 105 (May 17th). We see a lot happening here and in other countries, with travel restrictions and quarantining measures changing all the time. It is unlikely that countries will revert to large scale lockdowns.
This is partly because lockdown is seen by many to have done its job; partly because of its negative economic and social impacts; and partly because we know more about the effects of the individual interventions available. Mechanistic modelling methods help discriminate between the effects of the different interventions.
One of the key factors is the choice of interventions on the basis of longer-term outcomes, and the effect of actions taken today on future “herd” immunity of the population, which I covered in my July 31st blog post.
I mention again the influential March 16th Imperial College paper in this respect which, while published nearly 6 months ago, does give an insight into the complexity and capability of modelling methods and data sources and discrimination available to Government advisers.
Modelling on an overall national basis will need some enhancement to cope with the large number of local “spikes” and other events that we have been seeing.
Concluding comments
There are reasons for concern – the possibility that current spikes in cases might lead to a major “wave” in the epidemic; that autumn isn’t too far away; and that influenza and other related diseases such as SARS-Cov-2 are more prevalent in the autumn/winter months.
The BBC have reported that the return of students to Universities in the UK is expected to lead to a high risk of increasing the rate of Covid-19 cases. We will see.
I leave it to the Sky News summary to express closing thoughts, and some optimism.
“The fear among government scientists is that if the outbreak gets out of control among young people, it will eventually leak into the more vulnerable parts of the population. What might look like a divergence between cases and deaths is actually just a larger lag. To find the answer to that, the best places to look are France and Spain, where cases are rising fast, but deaths and hospitalisations are still low. But whatever happens, we should remember: this isn’t March all over again. We test so much more. We know so much more about treatment. And we all understand how to change our behaviour. That is cause for optimism as we face the next six months.“

Great summary Brian, not much to disagree with there and the point about how to model spikes associated with single super spreaders is well made, I have been following (and reporting) via the Tim Spector Zoe stuff for the last 5 months and wonder if that data might be of value in a bottom up model. doign a risk assessment on this, I worry that the start of the university year represents the single largest risk in the next 4-6 weeks. bringing together lots of young adults 18-22 from around the country has a track record of breaking existing heard immunity and creating outbreaks of mumps for example (https://www.bbc.co.uk/news/uk-england-nottinghamshire-47736643)
I can see no reason why this will do the same with C-19 and then spread back into general population.
It was a good read, thanks.
D
LikeLike
Txx, Dick, for you kind comments. We are in a new phase now, aren’t we, with so many different drivers for the passing of infections. tbh I thought that many Universities were going to use remote teaching and learning – hasn’t at least one Ivy League US University said that all courses will be online for the coming year/semester? If people were worried about schools then Universities would be far more of a danger given the “clientèle”. As far as modelling is concerned, it’s all going to be much more difficult. I assume the usual advisers are developing micro-models with sophisticated group dynamics to deal with the new landscape. I referred to a class of this kind of model in one of my previous posts – https://www.briansutton.uk/?p=3563 – where I referred to spatial metapopulation models, drawn from material by Gustavo Chowell, in his 2016 paper at https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5348083/pdf/nihms-802148.pdf. The Imperial College folks presumably have some of this in their armoury. That blog post, and another around the same time, at https://www.briansutton.uk/?p=3755, were to clear my mind on the curve-fitting approach which seems so popular. You’ll have seen my remarks about that in this post, but it took me quite a while to work out why I was uncomfortable with it. I just don’t think that a curve-fitting approach, top-down, is capable of responding to the dynamic changes we are seeing, at the micro-level. Discriminating between the relative effects and merits of different potential interventions just isn’t feasible using these methods. Even the Mechanistic modelling approach is going to find that difficult. I think curve-fitting is a productivity tool to allow rapid analysis of reported data across over 100 countries or regions to get some idea of where the infection graphs are going. But as the underlying causation and responses change (as we are seeing) I just don’t think it’s an appropriately detailed method. I’m only looking at the UK, but even just in this country, comprising 4 home countries and many local authorities, we can see revisions, corrections, competing and conflicting methods of recording and reporting cases and deaths. Even the much vaunted Excess Deaths measure (as reported by the Office for National Statistics) has its issues – Covid-19 deaths supplanting reduced deaths from some other causes, but storing up deaths (and possibly lingering severe symptoms in some people) for the future. The UK Government seems now to be recording three sets of deaths numbers (but still only reporting on one (another recently changed basis). And that’s for something as important as deaths. Cases are even worse in terms of clarity. It’s likely that the numbers of those to have been infected are vastly understated (as the post says). I feel a bit of a fraud in saying all this, not being a specialist in the medicine, the modelling or anything else closely related to the subject matter. But surely those at the higher pay scales can do better than we have seen! By the way, I also fill in my daily report for the Tim Spector/ZOE project, which does seem a very sensible way of getting to the data. Just as Apple mobility data can be used to help the analysis of individual and group interactions (I think the Imperial group (and Edinburgh) can use this in their models, so hopefully the ZOE data will be able to be built in somehow.It’s all a bit beyond my model’s capabilities, but I’m in touch with Alex de Visscherat Concordia Uni (author of the original model) to see how it can be taken forward another step or two. I’ve been busying myself joining a Python front-end (developed by Tom to grab the data from Worldometers) to the base Octave (MatLab) modelling code so that I can run not only the model but also the comparisons to current reported data with one button-press! Now THAT’s productivity! But it makes it easier to run the sensitivities without having to pull data in and/or copy outputs manually to Excel or Numbers or whatever. I seem to have gone on at length! Great to hear from you, txx!! Best wishes, Brian
LikeLike
Dick, I have added a brief refeence in the article to the BBc report today commenting on the return of students to Universities. Thank you for pointing it out!
LikeLike
Dick, I have added a reference to the BBC report today mentioning the possible effect of the return of students to universities on Covid-19 cases. Thank you for pointing it out! B
LikeLike