Introduction
This post covers the current status of my UK Coronavirus (SARS-CoV-2) model, stating the June 2nd position, and comparing with an update on June 3rd, reworking my UK SARS-CoV-2 model with 83.5% intervention effectiveness (down from 84%), which reduces the transmission rate to 16.5% of its pre-intervention value (instead of 16%), prior to the 23rd March lockdown.
This may not seem a big change, but as I have said before, small changes early on have quite large effects later. I did this because I see some signs of growth in the reported numbers, over the last few days, which, if it continues, would be a little concerning.
I sensed some urgency in the June 3rd Government update, on the part of the CMO, Chris Whitty (who spoke at much greater length than usual) and the CSA, Sir Patrick Vallance, to highlight the continuing risk, even though the UK Government is seeking to relax some parts of the lockdown.
They also mentioned more than once that the significant “R” reproductive number, although less than 1, was close to 1, and again I thought they were keen to emphasise this. The scientific and medical concern and emphasis was pretty clear.
These changes are in the context of quite a bit of debate around the science between key protagonists, and I begin with the background to the modelling and data analysis approaches.
Curve fitting and forecasting approaches
Curve-fitting approach
I have been doing more homework on Prof. Michael Levitt’s Twitter feed, where he publishes much of his latest work on Coronavirus. There’s a lot to digest (some of which I have already reported, such as his EuroMOMO work) and I see more methodology to explore, and also lots of third party input to the stream, including Twitter posts from Prof. Sir David Spiegelhalter, who also publishes on Medium.
I DO use Twitter, although a lot less nowadays than I used to (8.5k tweets over a few years, but not at such high rate lately); much less is social nowadays, and more is highlighting of my https://www.briansutton.uk/ blog entries.
Core to that work are Michael’s curve fitting methods, in particular regarding the Gompertz cumulative distribution function and the Change Ratio / Sigmoid curve references that Michael describes. Other functions are also available(!), such as The Richard’s function.
This curve-fitting work looks at an entity’s published data regarding cases and deaths (China, the Rest of the World and other individual countries were some important entities that Michael has analysed) and attempts to fit a postulated mathematical function to the data, first to enable a good fit, and then for projections into the future to be made.
This has worked well, most notably in Michael’s work in forecasting, in early February, the situation in China at the end of March. I reported this on March 24th when the remarkable accuracy of that forecast was reported in the press:

Forecasting approach
Approaching the problem from a slightly different perspective, my model (based on a model developed by Prof. Alex de Visscher at Concordia University) is a forecasting model, with my own parameters and settings, and UK data, and is currently matching death rate data for the UK, on the basis of Government reported “all settings” deaths.
The model is calibrated to fit known data as closely as possible (using key parameters such as those describing virus transmission rate and incubation period, and then solves the Differential Equations, describing the behaviour of the virus, to arrive at a predictive model for the future. No mathematical equation is assumed for the charts and curve shapes; their behaviour is constructed bottom-up from the known data, postulated parameters, starting conditions and differential equations.
The model solves the differential equations that represent an assumed relationship between “compartments” of people, including, but not necessarily limited to Susceptible (so far unaffected), Infected and Recovered people in the overall population.
I had previously explored such a generic SIR model, (with just three such compartments) using a code based on the Galbraith solution to the relevant Differential Equations. My following post article on the Reproductive number R0 was set in the context of the SIR (Susceptible-Infected-Recovered) model, but my current model is based on Alex’s 7 Compartment model, allowing for graduations of sickness and multiple compartment transition routes (although NOT with reinfection).
SEIR models allow for an Exposed but not Infected phase, and SEIRS models add a loss of immunity to Recovered people, returning them eventually to the Susceptible compartment. There are many such options – I discussed some in one of my first articles on SIR modelling, and then later on in the derivation of the SIR model, mentioning a reference to learn more.
Although, as Michael has said, the slowing of growth of SARS-CoV-2 might be because it finds it hard to locate further victims, I should have thought that this was already described in the Differential Equations for SIR related models, and that the compartment links in the model (should) take into account the effect of, for example, social distancing (via the effectiveness % parameter in my model). I will look at this further.
The June 2nd UK reported and modelled data
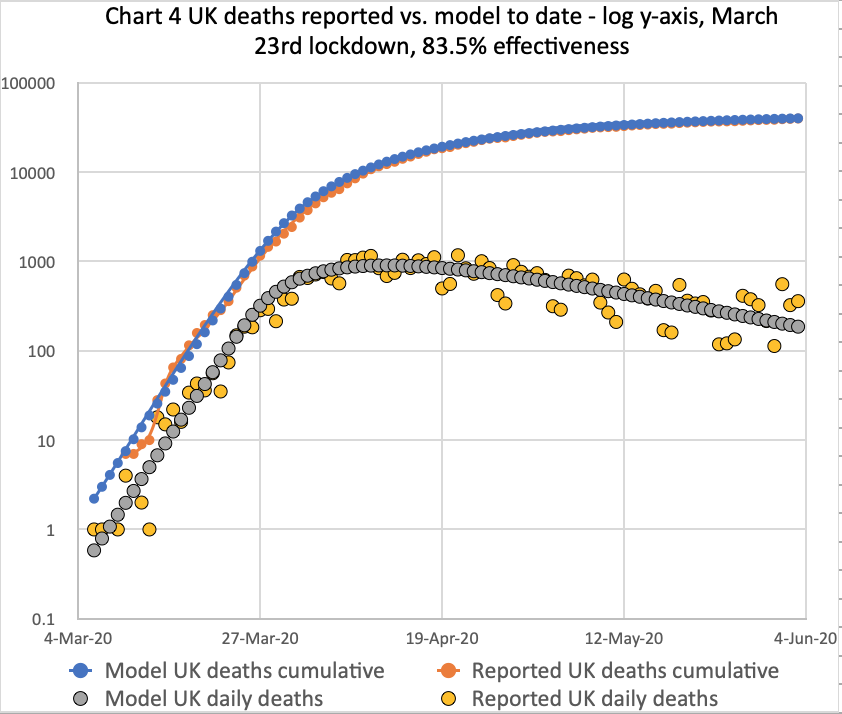
Here are my model output charts exactly up to, June 2nd, as of the UK Government briefing that day, and they show (apart from the last few days over the weekend) a very close fit to reported death data**. The charts are presented as a sequence of slides:


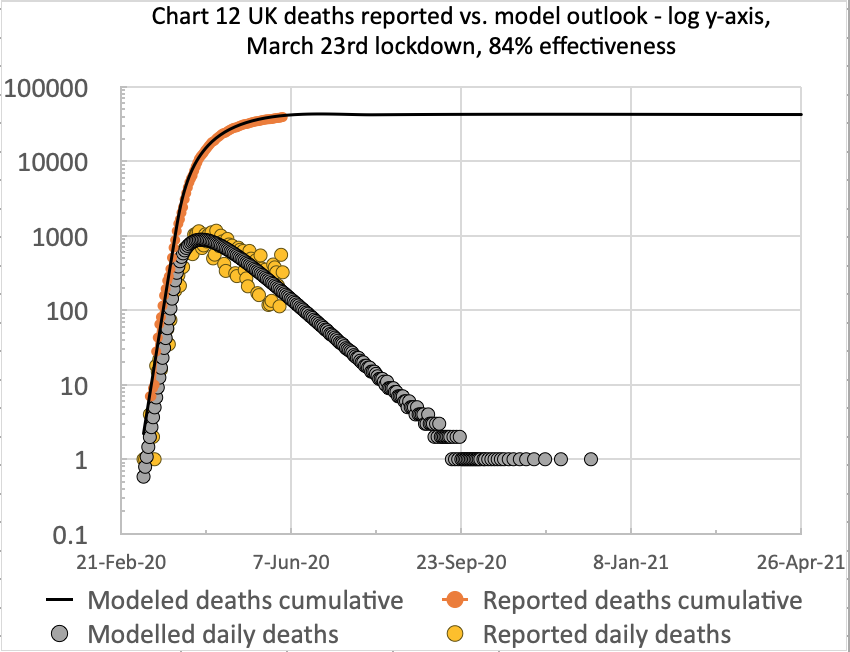
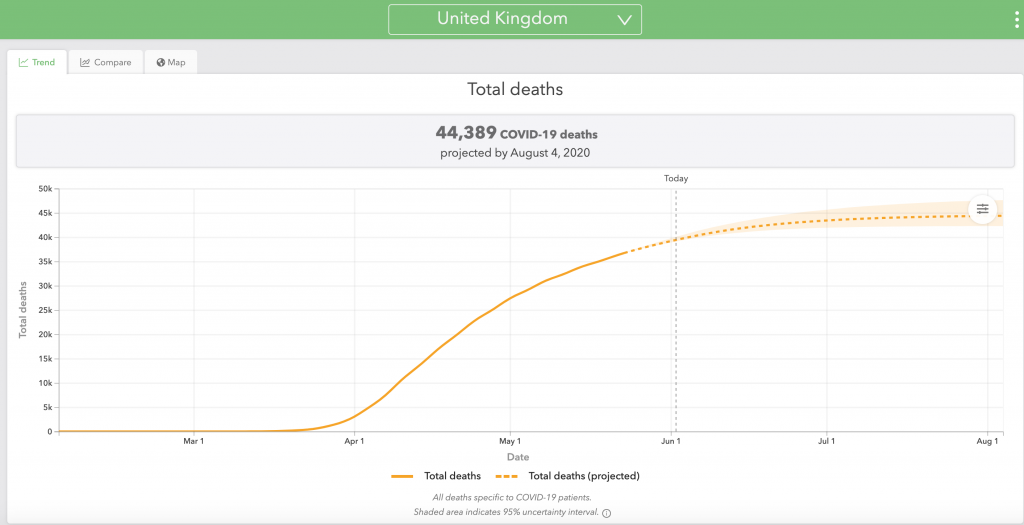
These charts all represent the same UK deaths data, but presented in slightly different ways – linear and log y-axes; cumulative and daily numbers; and to date, as well as the long term outlook. The current long term outlook of 42,550 deaths in the UK is within error limits of the the Worldometers linked forecast of 44,389, presented at https://covid19.healthdata.org/united-kingdom, but is not modelled on it.
**I suspected that my 84% effectiveness of intervention would need to be reduced a few points (c. 83.5%) to reflect a little uptick in the UK reported numbers in these charts, but I waited until midweek, to let the weekend under-reporting work through. See the update below**.
I will also be interested to see if that slight uptick we are seeing on the death rate in the linear axis charts is a consequence of an earlier increase in cases. I don’t think it will be because of the very recent and partial lockdown relaxations, as the incubation period of the SARS-CoV-2 virus means that we would not see the effects in the deaths number for a couple of weeks at the earliest.
I suppose, anecdotally, we may feel that UK public response to lockdown might itself have relaxed a little over the last two or three weeks, and might well have had an effect.
The periodic scatter of the reported daily death numbers around the model numbers is because of the reguar weekend drop in numbers. Reporting is always delayed over weekends, with the ground caught up over the Monday and Tuesday, typically – just as for 1st and 2nd June here.
A few numbers are often reported for previous days at other times too, when the data wasn’t available at the time, and so the specific daily totals are typically not precisely and only deaths on that particular day.
The cumulative charts tend to mask these daily variations as the cumulative numbers dominate small daily differences. This applies to the following updated charts too.
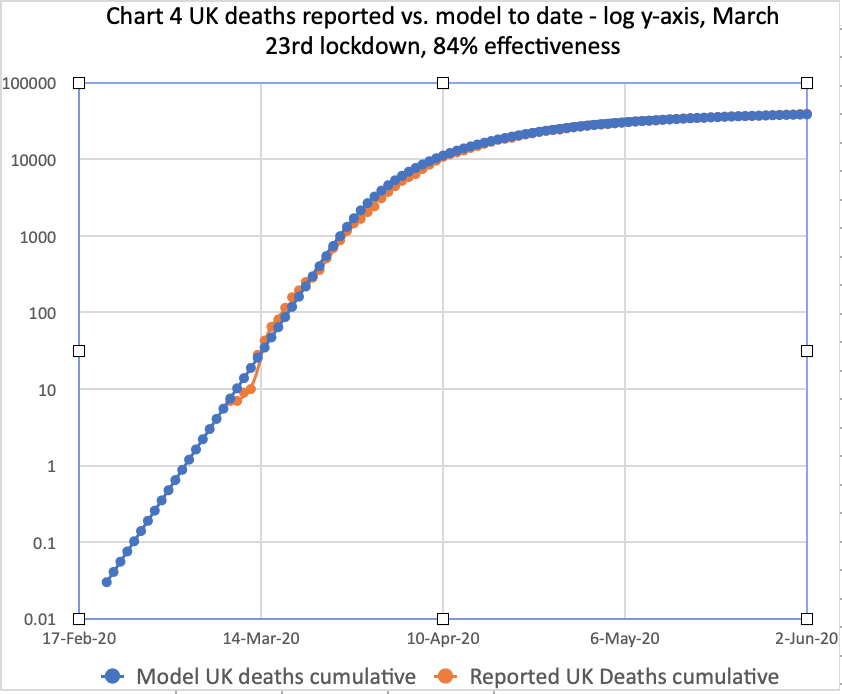
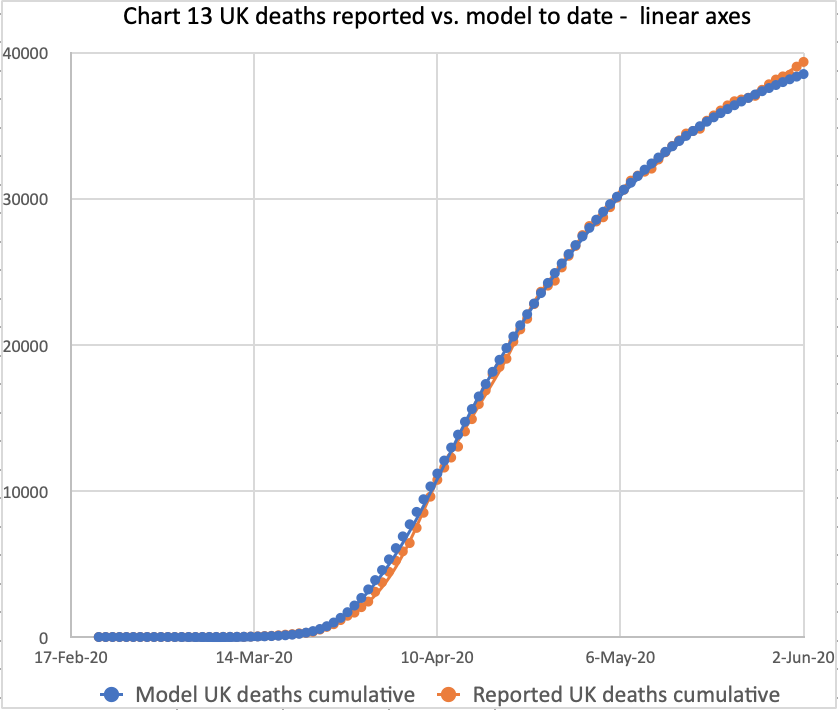
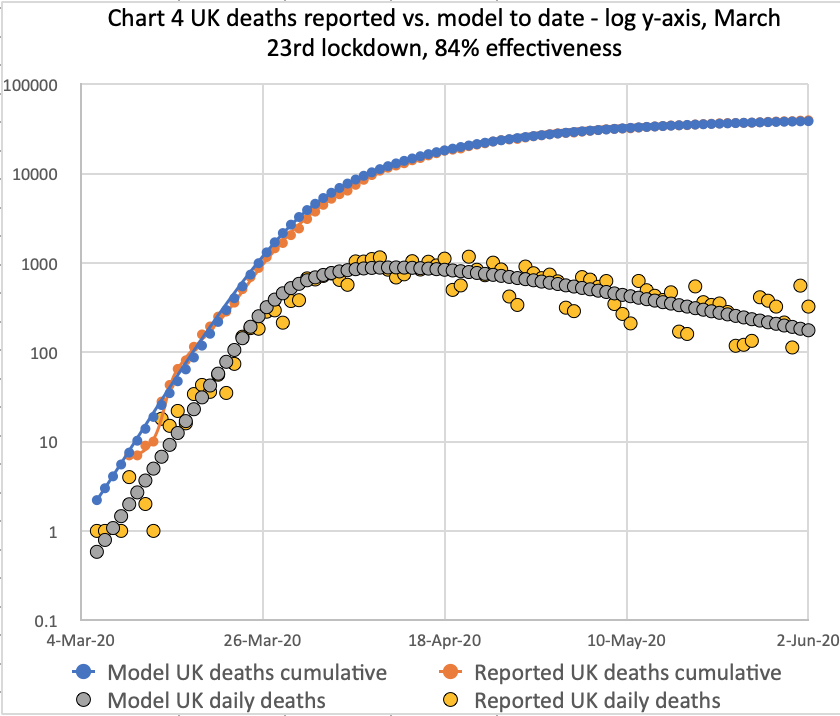
**June 3rd update for 83.5% intervention effectiveness
I have reworked the model for 83.5% intervention effectiveness, which reduces the transmission rate to 16.5% of its starting value, prior to 23rd March lockdown. Here is the equivalent slide set, as of 3rd June, one day later, and included in this post to make comparisons easier:
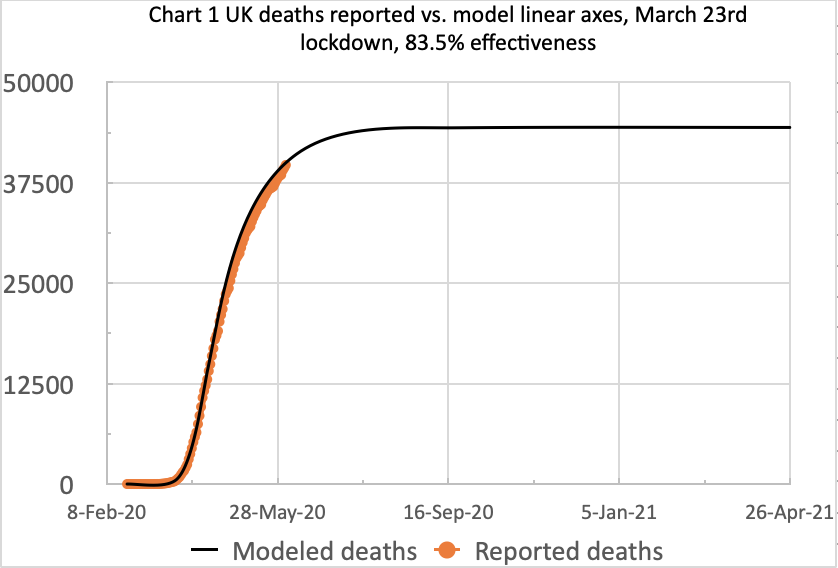

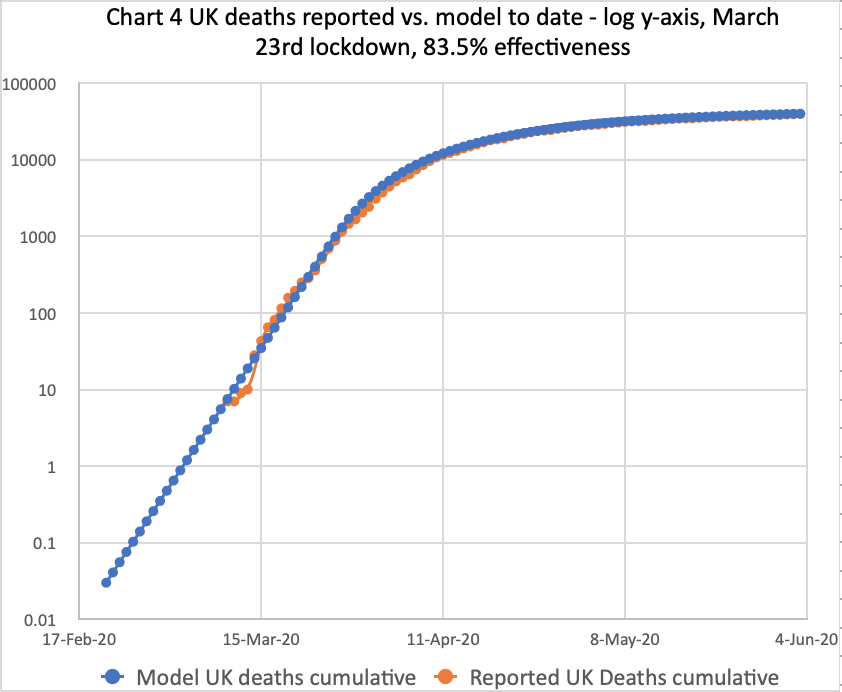
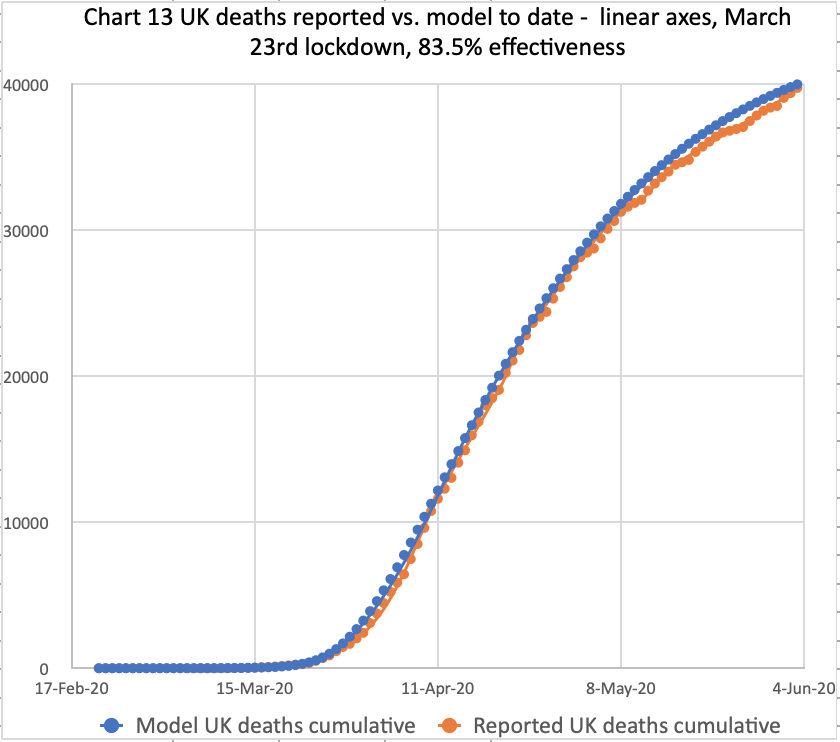
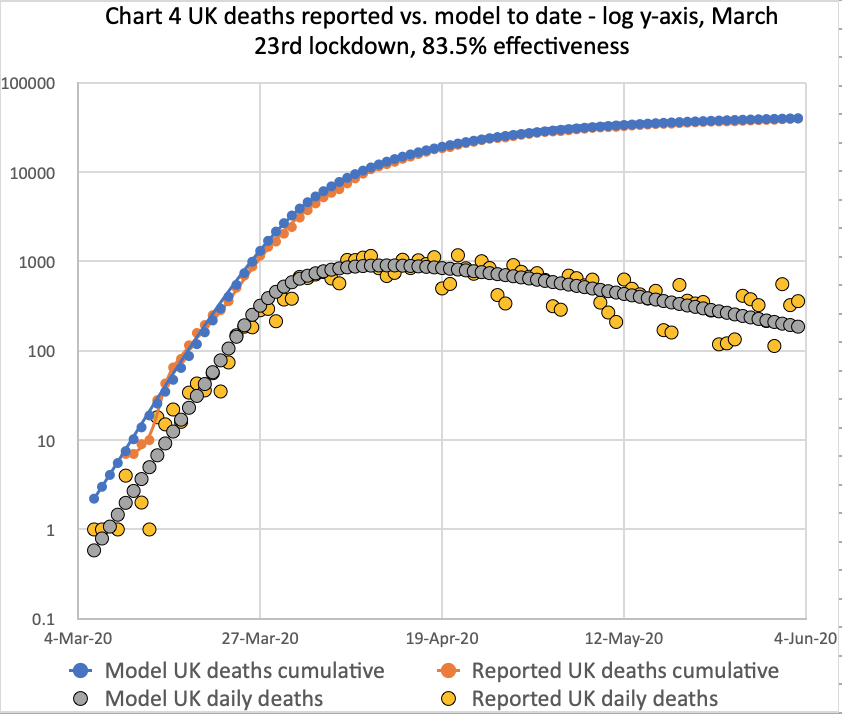
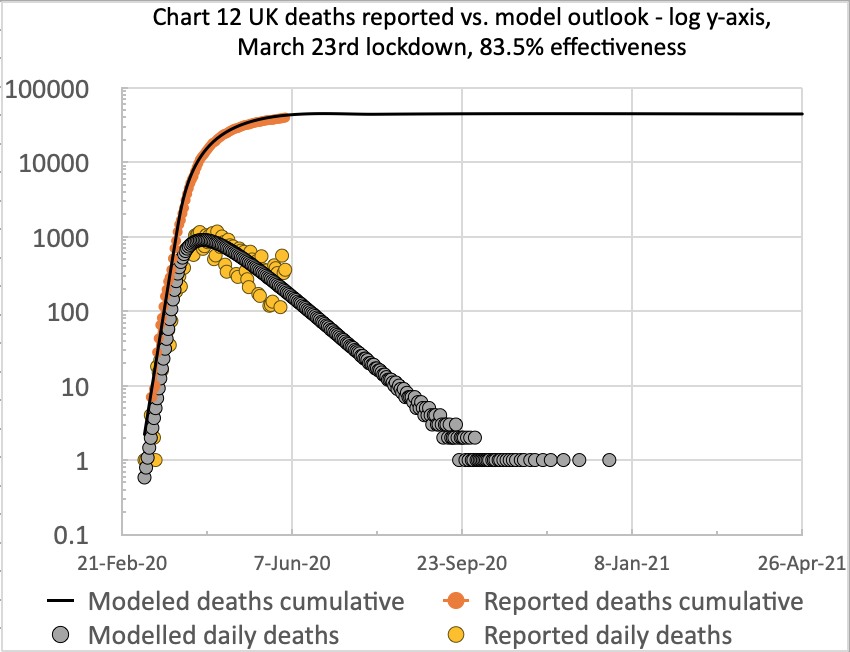
These charts reflect the June 3rd reported deaths at 39,728 and daily deaths on 3rd June of 359. The model long-term prediction is 44,397 deaths in this scenario, almost exactly the Worldometer forecast illustrated above.
We also see the June 3rd reported and modelled cumulative numbers matching, but we will have to watch the growth rate.
Concluding remarks
I’m not as concerned to model cases data as accurately, because the reported numbers are somewhat uncertain, collected as they are in different ways by four Home Countries, and by many different regions and entities in the UK, with somewhat different definitions.
My next steps, as I said, are to look at the Sigmoid and data fitting charts Michael uses, and compare the same method to my model generated charts.
*NB The UK Office for National Statistics (ONS) has been working on the Excess Deaths measure, amongst other data, including deaths where Covid-19 is mentioned on the death certificate, not requiring a positive Covid-19 test as the Government numbers do.
As of 2nd June, the Government announced 39369 deaths in its standard “all settings” – Hospitals, Community AND Care homes (with a Covid-19 test diagnosis) but the ONS are mentioning 62,000 Excess Deaths today. A little while ago, on the 19th May, the ONS figure was 55,000 Excess Deaths, compared with 35,341 for the “all settings” UK Government number. I reported that in my blog post https://www.briansutton.uk/?p=2302 in my EuroMOMO data analysis post.
But none of the ways of counting deaths is without its issues. As the King’s Fund says on their website, “In addition to its direct impact on overall mortality, there are concerns that the Covid-19 pandemic may have had other adverse consequences, causing an increase in deaths from other serious conditions such as heart disease and cancer.
“This is because the number of excess deaths when compared with previous years is greater than the number of deaths attributed to Covid-19. The concerns stem, in part, from the fall in numbers of people seeking health care from GPs, accident and emergency and other health care services for other conditions.
“Some of the unexplained excess could also reflect under-recording of Covid-19 in official statistics, for example, if doctors record other causes of death such as major chronic diseases, and not Covid-19. The full impact on overall and excess mortality of Covid-19 deaths, and the wider impact of the pandemic on deaths from other conditions, will only become clearer when a longer time series of data is available.”

2 thoughts on “Current Coronavirus model forecast, and next steps”