In my research on appropriate (available and feasible (for me)) modelling tools for epidemics, I discovered this paper by Prof. Alex de Visscher (to be called Alex hereafter). He has been incredibly helpful.
https://arxiv.org/pdf/2003.08824.pdf
Thanks to Alex including the MatLab code (a maths package I have used before) in the paper, and also a detailed description of how the model works, it qualifies as both available and feasible. There is also a GNU (public and free) version of MatLab (called Octave)) which is mostly equivalent in terms of functionality for these purposes, which makes it practical to use the mathematical tools.
In my communications with Alex, he has previously helped me with working out the relationship between the R0 Reproductive Number (now being quoted every time on Government presentations) and the doubling period for the case number of disease outbreak. I published my work on this at:
https://docs.google.com/document/d/1b9lB4RszIHJipS27raXxN6ECTFbihJ_fQFhdy5oCEwA/edit?usp=sharing
since mathematical expression are too cumbersome here on WordPress.
I would still say the Government is being a little coy about these numbers, saying that R0 is below 1 (a crucial dividing point between epidemic increase at R0>1 and epidemic slow down and dying out for R0<1). They now say (April 14th) it’s less than one outside hospitals and care homes, but not inside these places, as if (as Alex says) Covid-19 is not lethal, except for those people who die from it.
At least the Government have now stopped using graphs with the misleading appearance of y-axis log charts.
These following charts (unlike the original Government ones) make it pretty clear what kind of chart is being shown (log or linear) and also illustrate how different an impression might be given to a member of the public looking on a TV screen a) if the labelling isn’t there or obscurely referenced, and b) how the log charts to some extent mask the perception of steep growth in the numbers up until late March.




This chart from 14th April show the Government doing a little better over recent days in presenting a chart that visually represents the situation more clearly. Maybe the lower growth makes them more comfortable showing the data on linear axes.
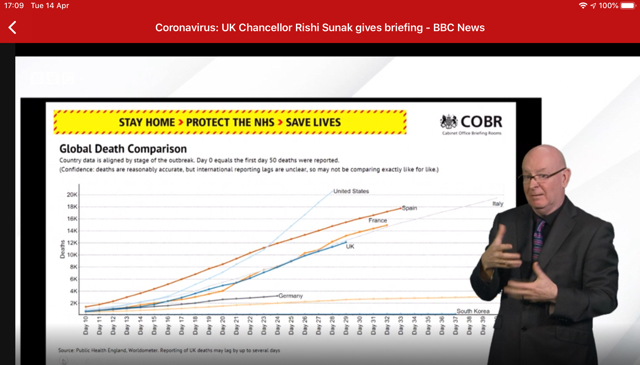
Linear y-axis scale
Alex de Visscher model description
I’ll try to summarixe Alex’s approach in the model I have begun to use to work with the UK numbers (Alex had focused on other countries (US and Canada nearer to home, plus China, Italy, Spain, Iran with more developed outbreak numbers since the epidemic took hold).
I have previously described the SIR (Susceptible, Infected and Recovered) 3-compartment model on this blog at https://www.briansutton.uk/?p=1296, but in this new model we have as many as 7 compartments: Uninfected (U), Infected (I), Sick (S), Seriously Sick (SS), Deceased (D), Better but not recovered (B) and Recovered (R). They are represented by this diagram:

Firstly, an overall infection rate r1 above can be calculated as a weighted sum of these four sub-rates;
r1 = (k11I+ k12S+ k13SS+k14B)U/P
where the infection rates k11, k12, k13, k14, are set separately, towards I, S, SS and B respectively, from healthy people, with the rates proportional to the fraction of uninfected people, compared to the total population, U/P.
All other transitions between compartments are assumed as first order derivatives with their own rate constants, with time t measured in days:
dU/dt = -r1; the rate of movement from Uninfected to Infected; and similarly, with in-/out-puts added and subtracted for other compartments:
| Transition rates between compartments | Differential equation |
|---|---|
| r1 = (k11I+ k12S+ k13SS+k14B)U/P | dU/dt = -r1 |
| r2=k2I for I to S transitions | with dI/dt = r1-r2 |
| r3=k3S for S to SS transitions | with dS/dt = r2-r3-r5 |
| r4=k4SS for SS to D transitions | with dD/dt = r4 |
| r5=k5S for S to B transitions | with dB/dt = r5+r6-r7 |
| r6=k6SS for SS to B transitions | with dSS/dt = r3-r4-r6 |
| r7=k7B for B to R transitions | with dR/dt = r7 |
Some simplifying assumptions are made: k12 = k11/2, k13 = k11/3 and k14 = k11/4, in other words scaling the infection rates to I from the other compartments S, SS and B, respectively, to the principal rate from U to I. (Subsequently k14 = 0*k11/4 was chosen to compensate for long contagious times once the SS median had been changed from to 10 days from 3.5 days. See below).
So we can recognise that the bones of the previous SIR model are here, but there is compartment refinement to allow an individual’s status to be more precisely defined, along with the related transitions.
The remaining parameters that can be set in the model are:
| Parameter (units) | Value |
|---|---|
| k11 (day-1) | variable |
| k2 (day-1) | loge(2)/5.1 |
| k3 (day-1) | k5/9 |
| k4 (day-1) | k6.(15/85) |
| k5 (day-1) | loge(2)/3.5 |
| k6 (day-1) | loge(2)/10 |
| k7 (day-1) | loge(2)/10 |
k11 was initially chosen by inspection of the observed doubling rate for the disease, and can be modified. k2 is based on the 5.1 day incubation rate observed in the paper by Lauer et al at https://annals.org/aim/fullarticle/2762808/incubation-period-coronavirus-disease-2019-covid-19-from-publicly-reported
k3/k5 is based on the assumption that 10% of the infected (I) become seriously sick (SS), whereas 90% get better without developing serious symptoms; less than the 80:20 proportion observed normally, because many with mild symptoms go unreported.
The k4/k6 ratio is set assuming a 15% non-survival rate for hospitalised cases.
k5 and k7 were set in the original model assuming a median rate of 3.5 days in each of the S and B stages before moving to the Recovered R stage (ie a median 7 days to recover from mild symptoms). k7 has now been set to a median of 10 days (implying a 13.5 day median for recovery from mild symptoms), and to compensate for the resulting long contagious times, k14 = 0*k11/4 has been chosen as stated above.
k6 is based on an SS stage patient remaining in that stage for 10 days before transitioning to B. Because the other pathway is to the Deceased D stage, the median is actually less, 8.5 days. This would be consistent with a mean duration of 12.26 days for getting better (B), which has been observed clinically.
Implementation of the model and further parameter setting
I have been operating the model with some UK data using Octave, but Alex was using the equivalent (and original licensed software) MatLab. He used the Ordinary Differential Equation Solver module in that software, ODE45, which I have used before for solving the astronomical Restricted Three Body Problem, so I know it quite well.
Just as all of the various Governmental, Johns Hopkins University and Worldometer published graphs and data are presented with a non-zero case baseline to start the simulations, as the lead-in time is quite long, so does this model. These initial parameters for the UK model so far are chosen as:
| Population P | 67.8 million |
| Initial infected number I | 100 |
| Initial Sick number S | 10 |
| Initial Seriously Sick number SS | 1 |
| Deaths D | 0 |
| Better B | 0 |
| Recovered R | 0 |
Thus there are (in the model) 111 infected people at the start, among the UK population of 67.8 million. This is still quite an early start for the simulation, with less than 10 known infections; the doubling time is estimated from the total of people in any infected stages at days 29 and 30 using a similar approach to the one I explained in that previous paper at https://docs.google.com/document/d/1xg4XY2wZPZFM2O5E76Y6zBPc_42l7PMPE4NF6XipDPQ/edit?usp=sharing
Thus the doubling time I called TD there is given by the equation:
TD loge2 = loge (C30 /C29)
where Cd is the reported number of cases on a given day d. Known cases are assumed to be 5% of infected cases I, 1/3 of sick cases S, 90% of seriously sick SS, 12% of recovering R and 90% of deceased cases D (not all are known but we assume, for example, that reporting is more accurate for SS and D). The calculated doubling time in the model is not sensitive to the choice of these fractions.
The critical factor R0, the Reproduction Number, can be calculated by a separate program module, for one infected patient, where the number of newly infected starting with that case can be calculated over time.
Solving the equations
The model, with the many interdependent parameter choices that can be made, solves the Differential Equations described earlier, using the initial conditions mentioned in Table 3. Alex’s paper describes runs of the model for different assumptions around interventions (and non-interventions), and he has presented some outcomes of National models (for example for China) on his YouTube channel at:
https://www.youtube.com/channel/UCSH5Bzb8Oa0BojCVMdXBW_g/
and Alex’s introduction to the model on that channel, for both China, and the world outside China which describes the operation of the model, and the post processing fitting to real data charts can be seen at
Alex’s early April update on Italy is at:
UK modelling
I’m at an early stage of working on a UK model, using Alex’s model and techniques, and the most recent UK data is presented at the UK Government site at:
https://www.gov.uk/government/publications/covid-19-track-coronavirus-cases
using the link to the total data that has been presented to date on that site. Unfortunately, each day I look, the presentation format changes (there used to be a spreadsheet which was the most convenient) and now the cumulative case count for the UK has increased suddenly by 3000 on top of today’s count. Death numbers are still in step. It isn’t hard to see why journalists might be frustrated with reporting by the UK Government.
I have, as a first cut, run the numbers through the model to get an initial feel as to outcomes. The charts produced are not yet annotated, but I can see the shape of the predictions, and I will just include one here before I go on to refine the inputs, the assumptions, the model parameters and the presentation.

In this chart, days are along the x-axis, and the y-axis in a log scale to base 10 (equal intervals are a multiple of 10 of the previous y-gridline) of numbers of individuals.
The red curve represents active cases, the purple curve the number of deaths D, and the yellow curve the number of seriously sick patients, SS. This chart is the simpler of the two that the model produces, but serves to illustrate what is going on.
I have not yet made any attempt to match the curves against actual UK outcomes for the first 50 days (say) as Alex has done for the other countries he has worked on.
The input choices for this version for the UK are:
interv_time = 52; % intervention time: Day 51 = March 23 – 1 = March 22
interv_success = 0.85; % fractional reduction of k11 during intervention
k11 = 0.39; % infection rate (per day)
k5 = log(2)/3.5;
k6 = log(2)/10;
k7 = log(2)/10;
fSS = 0.1; % fraction seriously sick
fCR = 0.04; % fraction critical
fmort = 0.015; % mortality rate
correction = 0.0012;
P = 67.8e6; % total population
The correction number is set to adjust for the correct starting number of cases. On Alex’s advice I set k11 = 0.39 which seems to provide a good initial match to death data.
In terms of numerical outputs, this is just a model, and hasn’t even been tuned, let alone fine tuned. The charts above reflect the output numbers in the model, which were:
doubling_time = -7511748644 – not relevant here for a declining epidemic;
final_deaths = 39,319 reached after a little over 100 days;
total_infections = 2,621,289 peaking at about 60 days
and I’m still making sense of these and working out some possible adjustments. Firstly I want to match with real data up to to date, so there is some spreadsheet and plotting work to do.
Now the model has been run, there can be a combinatorial number of changes that could be made to get the model to fit the first 50 days’ data.
The work has only just started, but I feel that I have a worthwhile tool to begin to parallel what the Government advisers might be doing to prepare their advice to Government. Watch this space!

6 thoughts on “Making a little progress with a Covid-19 Coronavirus model and real data”