In the news today (coincident with my current work on this post) we can see how important the measures taken through social distancing, self-isolation and (partial) lockdown are to reducing the rate of infections. So far, the SHTM researchers say “…the R0 could be cut…” and “likely lead to a substantial impact and decline…” – i.e. we are on track theoretically, but we are yet to see the full benefits. It is still my view, expressed in my last post, that in the UK, we are still at an R0 figure of 2.5-3.5, with a doubling period of 2-3 days (2 and 3 are VERY different figures in this exponential context, as we see from my earlier posts).

While it’s a small study, it’s interesting to note the intention to reduce the R0 Reproduction Number (that I talked about in my last post), equivalent to the average number of people a person infects in the “susceptible” part of the population (those not yet infected, or recovered). The SIR model I have been working on reflects this concept in generic terms, as described below.
The model is, in effect, a Markov Chain solution to the infection activity, where each state of the SIR (Susceptible-Infected-Recovered compartmentalised) population at time t+δt depends only on the previous state at time t, solved through Monte-Carlo sampling for the statistical behaviour (ie not analytically), using an iterative procedure called the Gillespie algorithm, described last time, to solve the differential equations of the SIR model.
Thanks to some great work by Tomasz Knapik (Sutton family friend) I can show show a couple of new charts relating to variations in the data for the Gillespie algorithm for solving the SIR equations I talked about in my previous post.
You’ll recall this chart from last time, where for a population of 350, with infection rate α, and recovery rate β set, the progress of this simple SIR model shows the peak in infections from 1 index case, with a corresponding reduction in susceptible individuals, and an increase in recoveries until the model terminates with all individuals recovered, and no susceptible individuals left.

I drew this with a log scale (base 10) for time, because in this model, with the default input data, not much happens for quite a while from time t=0, until the infections take off rapidly at t=0.1 (on the generic time scale) and reach a peak at t=0.3. The model is fully played out at t=10. The peak for infections, out of a population of 350, is 325, for this input data:

Key parameters for the basic SIR model are:
The total population, N; the rate of infection α; and the rate of cure β.
Base default data for the simulation is for 1 index infected case at t=0, and the “Spatial Parameter” V, set at 100 in the generic units used by the model. I’ll talk more about this parameter in a later post.
A larger V reduces the infection growth through “distancing” the infected cases from the susceptible compartment of the population, and a smaller V increases the pace of infection by reducing the distance in general terms.
The equations for the simple SIR model being analysed, for a limited total population N, where:
N = nS + nI + nR , the sum of the compartmentalised Susceptible, Infected and Recovered numbers at any time t;
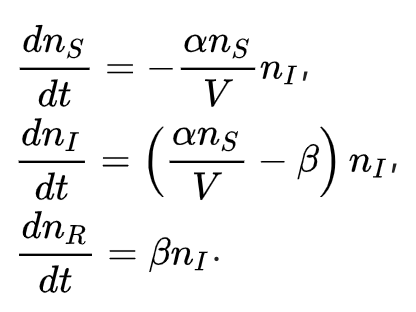
With linear scales for both the x-axis (time) and the y-axis (cases) we can see, in the following two charts, that a change in the spatial parameter (V) in the differential equations above does precisely what the Government is trying to achieve with its measures regarding self-isolation, social distancing and reduction in opportunities for people to meet other than in their household units.
Firstly, in the the modified Python Gillespie model (the Knapik, Sutton & Sutton model!) for the case illustrated above, but with linear axes:

Second, I change the spatial parameter, V, to 1000, for illustrative purposes:

We see above that the spatial parameter, representing increasing “social distancing” in this SIR application, does what is intended by the social distancing behaviour encouraged by most Governments – it pushes the peak of the infections from t=0.3 further out, towards t=2, and also flattens the peak, down to about 140 cases, from 325 before.
My task now is to relate the following key parameters of this situation:
First of all, the Reproduction Number R0 (the number of people one person might infect).
Secondly, the generation interval (how long it takes that infection to take effect (a vital number, and the subject of some difference in the literature between medical practitioners on the one hand, and demographic / biological practitioners on the other). An epidemiological formula, and a demographic/ecological/evolutionary biology formula can both be used to assess the generation interval, from R0, but can lead to very different results, to summarise a point made in paper on exactly this topic (ref. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1766383/).
Third, the doubling period – what is the right logarithmic multiplier in the Johns Hopkins University charts, given R0?
And lastly, the time taken, relatively, to see the R0 come down to a value near 1, when the epidemic stabilises and would tend to die out if R0<1 can be achieved.
No account is taken by my SIR model of recovery and re-infection; the SEIS model mentioned last time, or a variation of it, would be needed for that.
No-one is clear, furthermore, as to the seasonality of this Coronavirus, Covid-19, with regard to winter and summer, ambient humidity and temperatures, or the likelihood of mutation.

4 thoughts on “Some progress with the Gillespie SIR model – Coronavirus”